Regroupement rationnel des données pour une utilisation efficace des graphiques XbarR de contrôle des moyennes et des plages de sous-groupes
Source : Article aimablement fourni par le Dr Donald Wheeler : [35] Regroupement rationnel. Fondements conceptuels des diagrammes de comportement de processus / Sous-groupement rationnel. Le fondement conceptuel des diagrammes de comportement des processus, Donald J. Wheeler.
Traducteur et rédacteur scientifique : Sergey P. Grigoryev
Le libre accès aux articles ne diminue en rien la valeur des matériaux qu'ils contiennent.
Un aspect important de l’utilisation efficace des cartes de contrôle est leur capacité à répondre aux bonnes questions. Pour ce faire, la méthode de répartition des données en sous-groupes doit correspondre à la structure des données. Cela signifie généralement que les données provenant d'une « petite zone » - espace, temps, lot de production - doivent être regroupées dans chaque sous-groupe afin que les données au sein du sous-groupe soient aussi homogènes que possible. L'accent mis sur la minimisation des variations au sein des sous-groupes vient du fait que c'est cette variation qui est utilisée dans le calcul des limites de contrôle. Les limites de contrôle dépendent de la plage moyenne, qui à son tour dépend des plages de groupes individuels, qui reflètent les variations au sein des sous-groupes. C'est la variation au sein des sous-groupes qui est utilisée pour fixer les limites de contrôle, qui déterminent le degré de variation acceptable entre les sous-groupes.
La question posée par la carte de contrôle des moyennes est la suivante : « Les moyennes du groupe varient-elles plus qu'elles ne le devraient, en fonction de la variation au sein du groupe ? » En d’autres termes : « Compte tenu de la variabilité au sein des sous-groupes, les différences entre les moyennes des groupes sont-elles détectables ?
Le tableau des plages de sous-groupes demande : « La variation au sein des sous-groupes est-elle cohérente d’un sous-groupe à l’autre ? » Ou, pour le dire autrement : « Étant donné l’hypothèse d’une variation moyenne au sein des sous-groupes, les différences de variation entre les sous-groupes sont-elles détectables ?
La différence entre ces deux questions sera illustrée par plusieurs exemples.
Épaisseur de feuillle
La feuille de vinyle de 30 pouces (762 mm) de large utilisée pour fabriquer le revêtement de panneau rembourré a été extrudée sous le contrôle d'un contrôleur de processus automatique. Le périphérique d'entrée de ce contrôleur de processus automatique était un scanner bêta traditionnel qui mesure l'épaisseur du vinyle. L'ingénieur souhaitait étudier les lectures d'épaisseur le long d'une piste située à 10 pouces du bord gauche de la feuille de vinyle. Il a donc collecté toutes les données de cette piste et les a tracées sur une carte de référence de moyenne et de plage de sous-groupe XbarR, en utilisant des sous-groupes de taille quatre. .
En utilisant un sous-groupe de quatre personnes, il a veillé à ce que chaque sous-groupe représente environ deux minutes de travail de processus. Selon lui, cela a permis l'apparition de variations normales (variations aléatoires dues à des causes communes) dans le processus d'extrusion dans chaque sous-groupe. Le diagramme de contrôle moyen de la figure 1 montre que le contrôleur automatique a ajusté le processus de haut en bas par cycles d'environ 20 minutes. Bien que l’épaisseur moyenne soit de 48,5 mm, elle pourrait atteindre 49,5 mm en cinq ou six minutes avant de chuter à 47 mm au bout de six minutes. Ce changement d'épaisseur affectait la façon dont le vinyle chaufferait et s'étirerait lors de la formation du vide. Ce changement d'épaisseur a créé du déchet à l'étape suivante, mais en moyenne le vinyle avait la bonne épaisseur !
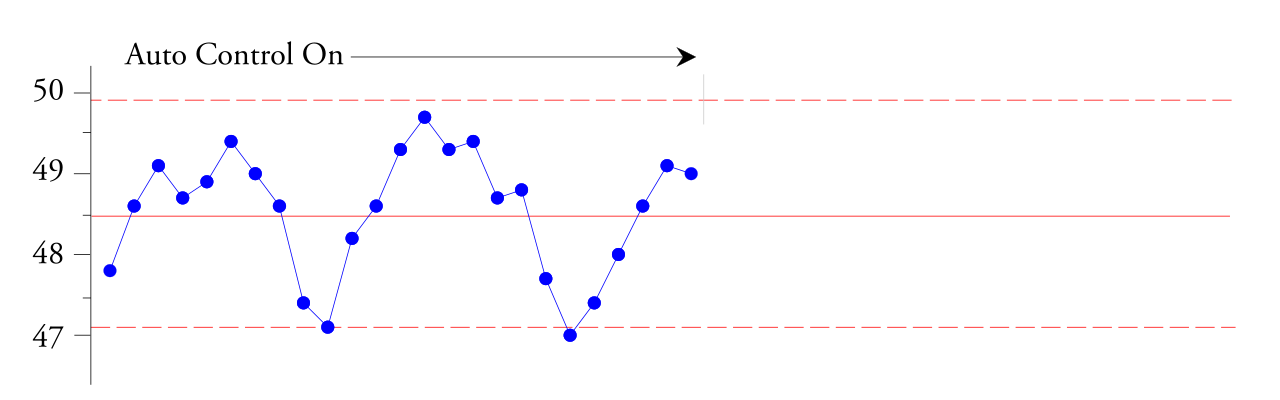
Riz. 1. Carte de contrôle XbarR des sous-groupes d'épaisseur moyenne des feuilles de vinyle lors du contrôle automatique.
Les points situés dans les limites de contrôle montent et descendent pour nous indiquer que ce contrôleur de processus automatique n'est pas suffisant. amorti , ne maintient pas une bonne réponse à l’état stable et a besoin d’aide. Selon l'ingénieur qui a créé cette carte de contrôle XbarR, il est facile de « reconnaître l'onde sinusoïdale » que nous observons. Sur la base du phénomène observé sur la figure 1, l'ingénieur a éteint le contrôleur automatique du processus. Au cours des 45 minutes suivantes, il a reçu de nouvelles valeurs, illustrées à droite sur la figure 2.
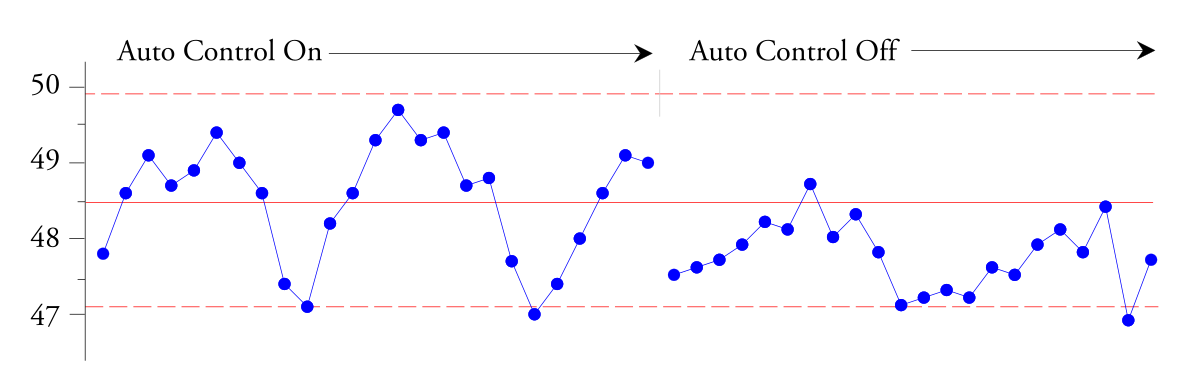
Riz. 2. Graphique de contrôle XbarR des sous-groupes d'épaisseur moyenne des feuilles de vinyle (suite).
Cela a confirmé qu'environ la moitié de la variation de l'épaisseur de la tôle était due au contrôleur automatique du processus. Étant donné que ces variations entraînent une sortie défectueuse, ce contrôleur de processus automatique doit être correctement configuré pour éliminer ces cycles de 20 minutes. Remarquez comment le cheminement depuis l'interprétation du graphique jusqu'à la formulation de l'action requise dépend à la fois du contexte des données et de la manière dont les données sont organisées en sous-groupes.
Temps jusqu'au couple maximum
Pour caractériser les propriétés de durcissement des lots de mélange de caoutchouc, un échantillon de chaque lot doit être testé en laboratoire. Ce test mesure le couple d'un échantillon de caoutchouc lors de son durcissement. Le résultat du test était le temps de durcissement requis pour atteindre le couple maximal. Étant donné que chacun des trois opérateurs produisait cinq charges de caoutchouc par quart de travail, le laboratoire a décidé d'utiliser les cinq valeurs quotidiennes de chaque opérateur comme sous-groupes. Cela a abouti à un sous-groupe par équipe, la variation au sein d'un sous-groupe étant la variation d'un lot à l'autre pour chaque opérateur, et la variation entre les sous-groupes étant la variation d'un opérateur à l'autre et d'un jour à l'autre. Étant donné que tous les opérateurs fabriquaient le même produit en utilisant la même usine de caoutchouc, nous nous attendions à voir un processus prévisible lors de la construction du graphique XbarR des moyennes et des plages des sous-groupes.
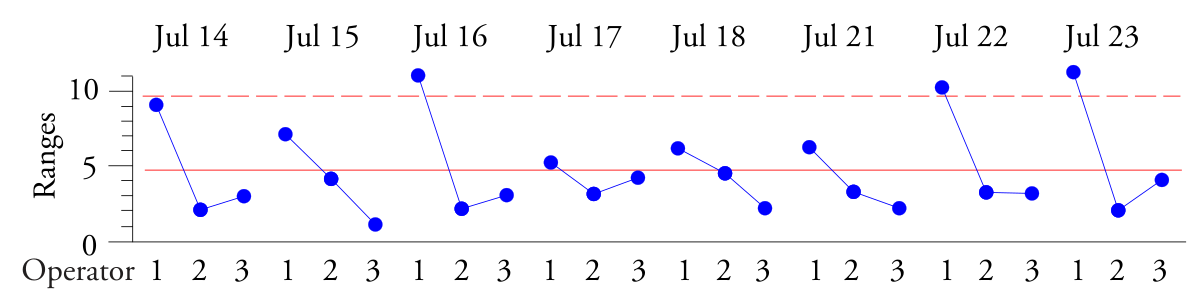
Riz. 3. Contrôlez la carte R des plages de sous-groupes pour le temps jusqu'au couple maximum.
La carte R des plages de groupes montre un modèle répétitif haut-bas-bas. Les lots produits par l'opérateur 1 présentent plus de variations que les lots produits par les opérateurs 2 et 3. Bien que l'opérateur 1 soit un opérateur senior avec 30 ans d'expérience, il n'a pas mélangé correctement ses lots. Il s'est avéré que c'était parce que l'opérateur 1 perdait la vue et ne pouvait pas voir assez bien pour mixer manuellement.
Encore une fois, la clé de l’interprétation des données consiste à organiser les données sur une carte de contrôle. La carte de contrôle XbarR des plages de groupes montre le manque de cohérence au sein des sous-groupes, et l'identification de chaque sous-groupe avec une seule déclaration nous permet de comprendre le modèle présenté dans la figure 3. C'est l'organisation des données qui détermine quels problèmes seront abordés dans le Carte de contrôle XbarR des moyennes et des plages de sous-groupes. Les changements d'emplacement qui se produisent entre les sous-groupes seront affichés sur la carte X des moyennes des sous-groupes. Les changements de variation qui se produisent au sein des différents sous-groupes seront affichés dans la carte R des plages de groupes. Dans chaque cas, c'est la variation au sein des sous-groupes qui détermine le critère de détection des différences éventuelles. Comprendre cela est la clé pour analyser efficacement les données d’observation.
Dans le premier exemple ci-dessus, il s'agissait d'un circuit séquentiel proposant une expérience simple pour désactiver un contrôleur de processus automatique. Dans le deuxième exemple, c’est une approche adaptée à la structure des données qui a conduit à la découverte d’un opérateur aveugle. Dans les deux cas, l’interprétation des schémas dans leur contexte a conduit à des découvertes. La volonté de penser de cette façon, qui est cohérente avec la manière dont les données sont collectées et construites, ne peut pas être programmée. Cela dépend de quelqu'un qui prend le temps et les efforts nécessaires pour examiner les graphiques et y réfléchir. Cela a toujours été et fera toujours partie intégrante de l’utilisation efficace des cartes de contrôle du comportement des processus.
Pour certains ensembles de données, le sous-groupement rationnel sera assez simple. Cependant, pour certains ensembles de données, il peut exister plusieurs manières possibles de diviser les données en sous-groupes. L'exemple suivant entre dans cette catégorie.
Têtes de joint moulées par injection
Le moulage par injection est utilisé pour fabriquer le joint pivotant quatre pièces à la fois. Au moment de la collecte de ces données, cette méthode de fabrication représentait des changements tant au niveau des matériaux que de la technologie. Par conséquent, avant de se lancer dans la production de masse, il était nécessaire de se soumettre à une certification des processus. Dave, le responsable, a décidé d'utiliser des listes de contrôle de comportement pour évaluer le processus avant la certification.
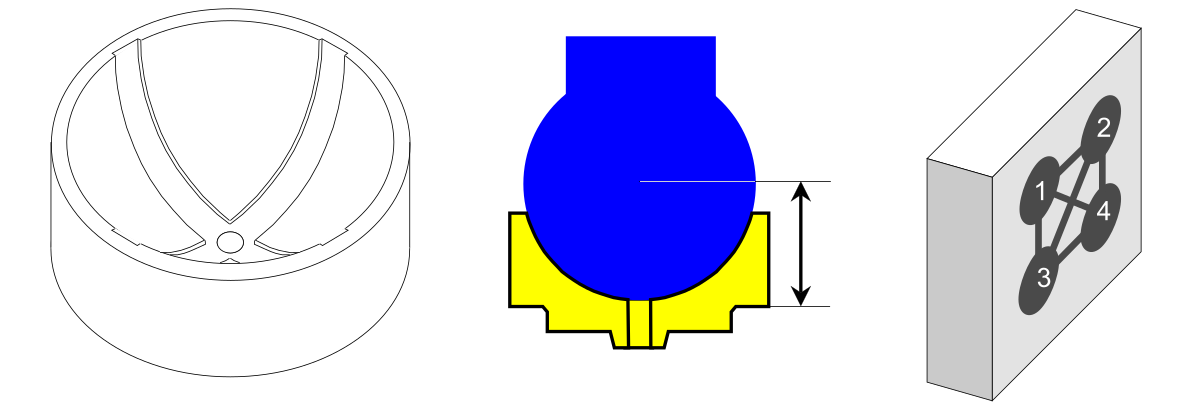
Riz. 4. Attelage à bille, épaisseur et moule comportant 4 cavités.
Puisqu’il n’y avait qu’un seul moule, une seule presse et un seul opérateur étaient impliqués dans le processus de certification. Les données étaient l'épaisseur effective de l'attelage à rotule, mesurée en centièmes de millimètre. Étant donné qu'un côté de l'attelage à rotule était concave, une jauge spéciale a dû être conçue et fabriquée pour mesurer cette épaisseur. Les mesures au calibre montrent une épaisseur supérieure à 12,00 millimètres. Quatre fois par jour, Dave se rendait à la presse et récupérait les pièces produites par cinq cycles de presse consécutifs. Comme chaque cycle produisait quatre pièces (une dans chaque cavité), il devait mesurer 20 pièces toutes les deux heures. En faisant preuve de prudence, Dave a gardé une trace du cycle et de la cavité d'où provenait chaque pièce.
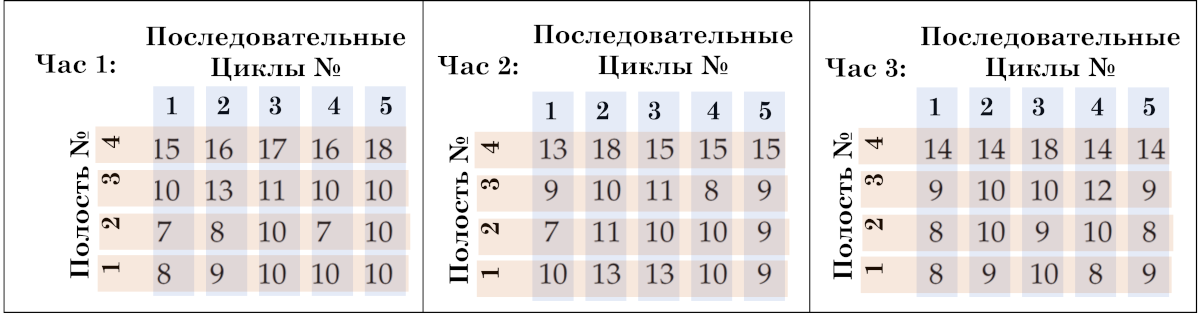
Riz. 5. Structure des données horaires sur l'épaisseur des accouplements à billes. Heure, Cécles Consécutifs, Cavité.
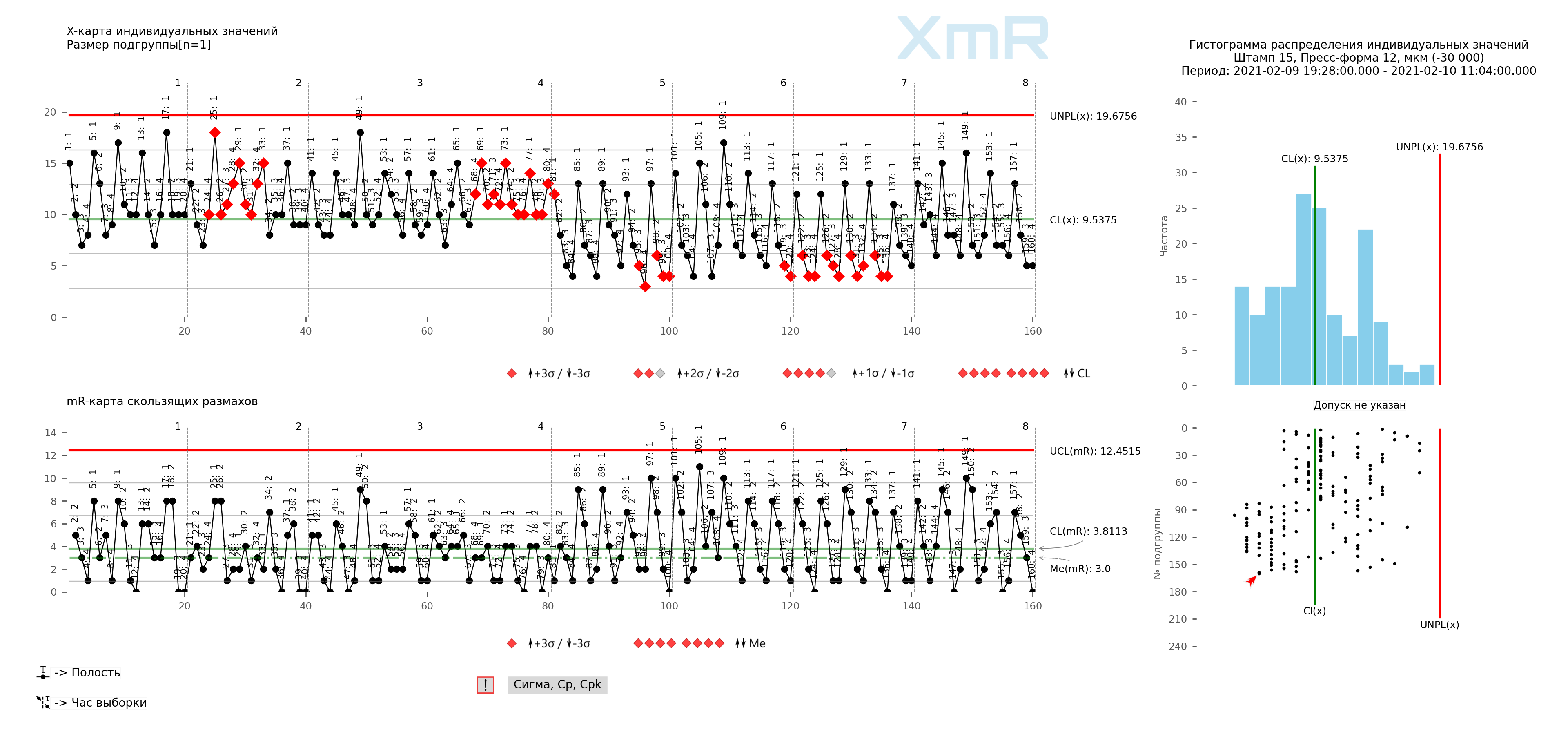
Riz. 6. Structure des données horaires sur l'épaisseur de l'attelage à bille, sur le diagramme d'avancement du processus (graphique XmR des valeurs individuelles et des plages de glissement). Diviseurs verticaux : Heure, signatures de tous les points : Cavité du moule. Le dessin a été préparé à l'aide de notre logiciel développé « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » .
Il existe trois sources identifiables de variation dans ces données. Il existe une variation horaire, qui est représentée par différents ensembles (blocs) de 20 valeurs dans la figure 5. Il existe une variation d'un cycle à l'autre, qui est représentée par différentes colonnes dans la figure 5 (1, 2, 3, 4, 5). Et il existe une variation d'une cavité à l'autre, qui est représentée par différentes lignes sur la figure 5 (1, 2, 3, 4).
Nous examinerons les différentes manières de les regrouper pour la carte de contrôle XbarR des moyennes et plages de sous-groupes, ainsi que l'impact de chaque organisation des données en sous-groupes sur l'interprétation des cartes de contrôle. Pour le processus de certification, Dave a collecté des données pendant six jours. Par souci de concision, nous n’utiliserons que les données des deux premiers jours.
L'ensemble complet des données et la première organisation en sous-groupes sont présentés dans la figure 7. Chaque colonne de quatre valeurs permet de définir un sous-groupe, de sorte que nos 160 valeurs sont organisées en 40 sous-groupes de taille n=4. Les données pour différentes heures (1, 2, 3, etc.) se trouvent dans différents sous-groupes. Quand vous changez d'horaires, vous changez de sous-groupes. Ainsi, dans cette première organisation des données en sous-groupes, on peut dire que des différences horaires (ainsi que des différences journalières) apparaissent entre les sous-groupes. Ici, le graphique des moyennes XbaR posera les questions suivantes :
Question n°1 : Y a-t-il des différences notables entre les heures ou les jours ?
Dans la figure 8, les données de différents cycles (1, 2, 2, 4, 5) sont réparties dans différents sous-groupes. Quand on change de cycle, on change de sous-groupes. On peut donc dire que des différences entre les cycles apparaissent entre les sous-groupes dans cette première organisation de ces données. Ici, le graphique du sous-groupe moyen posera également la question suivante :
Question n°2 : Y a-t-il des différences notables entre les cycles ?
Sur la figure 8, les données de différentes cavités (1, 2, 3, 4) se trouvent dans le même sous-groupe. Lorsque vous changez d'empreintes, vous n'avez pas besoin de changer de sous-groupes. On peut donc dire que des différences entre cavités apparaissent au sein de sous-groupes dans cette première organisation de ces données. Donc ici, le tableau des plages de groupes posera la question suivante :
Question n°3 : Les différences entre les cavités sont-elles cohérentes ?

Riz. 7. La première façon d'organiser les données en sous-groupes.
Valeur moyenne - 9,54 ; la plage moyenne est de 7,63, ce qui donne les limites de contrôle illustrées à la figure 8. En cassant la ligne du graphique, nous facilitons la lecture en donnant à nos yeux une référence à chaque heure séparément. Bien qu’aucun point ne dépasse les limites, il existe un signal clair dans le graphique des moyennes du sous-groupe. Lorsque 20 moyennes sur 20 se situent au-dessus de la ligne médiane, suivies de 19 sur 20 en dessous de la ligne médiane, il y a une réelle différence entre le premier et le deuxième jour. Le graphique de plage de sous-groupes peut également afficher les différences quotidiennes. Nous répondons donc à la question n°1 (Y a-t-il des différences notables entre les heures ou les jours ?) par un oui définitif, nous répondons à la question n°2 (Y a-t-il des différences notables entre les cycles ?) par la négative, et répondons à la question n°3 (Les différences sont-elles cohérentes ? ? entre les cavités ?) probablement « non ».
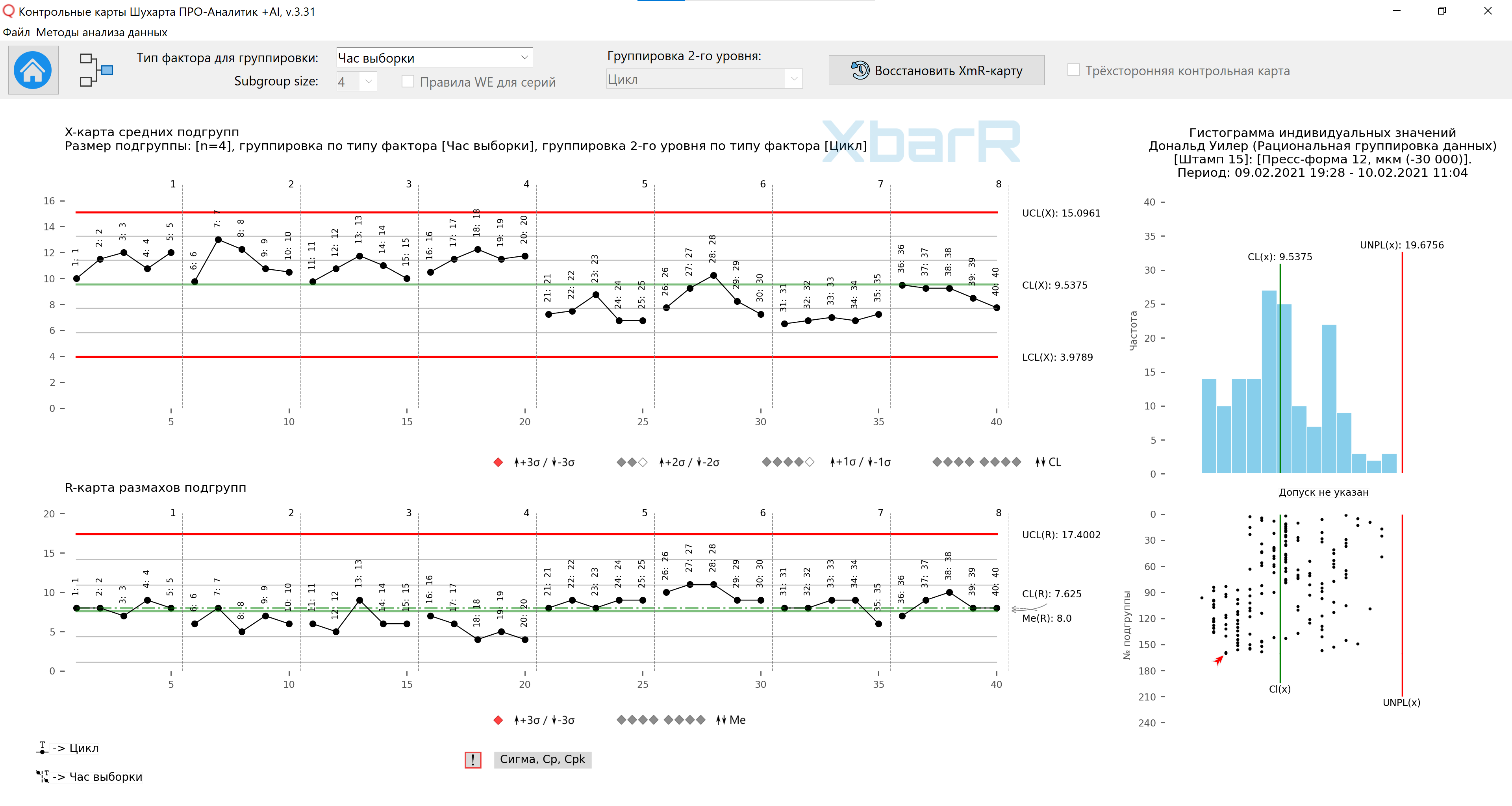
Riz. 8. Carte des moyennes et des plages de sous-groupes pour la première méthode d'organisation des données en sous-groupes. Lignes verticales divisant les séries avec des valeurs de 1 à 8 - Heures d'échantillonnage, signatures de tous les points - N° de cycle Le dessin a été réalisé à l'aide de notre développé « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » en utilisant un unique fonctions d'automatisation pour un regroupement rationnel des données construire un graphique XbarR des moyennes et des plages de sous-groupes par le type de sources de variation sélectionné (colonne avec facteurs) et la taille des sous-groupes.
La deuxième façon d'organiser les données en sous-groupes
Une deuxième façon d'organiser ces données est présentée dans la figure 9. Là, chaque ligne de cinq valeurs est utilisée pour définir un sous-groupe, nous nous retrouvons donc avec 32 sous-groupes de taille n=5. Ici, les données de différentes horloges (1 :, 2 :, 3 :, etc.) sont réparties dans différents sous-groupes. Quand vous changez d'horaires, vous changez de sous-groupes. Ainsi, dans la seconde organisation, on peut dire que des différences horaires (et quotidiennes) apparaissent entre les sous-groupes. Ici, le graphique du sous-groupe moyen posera la question suivante :
Question n°4 : Y a-t-il des différences notables entre les heures ou les jours ?
Dans la figure 9, les données de différents cycles (1, 2, 3, 4, 5) se trouvent dans le même sous-groupe. Lorsque vous changez de cycle, vous n'avez pas besoin de changer de sous-groupe. Ainsi, on peut dire que des différences entre cycles apparaissent au sein des sous-groupes dans la deuxième organisation de ces données. Ici, le diagramme de plage de groupe posera la question suivante :
Question n°5 : Les différences entre les cycles sont-elles cohérentes ?
Sur la figure 9, ces différentes cavités (1, 2, 3, 4) se trouvent dans différents sous-groupes. Lorsque vous changez d'empreintes, vous changez de sous-groupes. Ainsi, on peut dire que des différences entre cavités apparaissent entre sous-groupes dans la deuxième organisation de ces données. Ici, le graphique de la moyenne du sous-groupe pose également la question suivante :
Question n°6 : Y a-t-il des différences notables entre les cavités ?
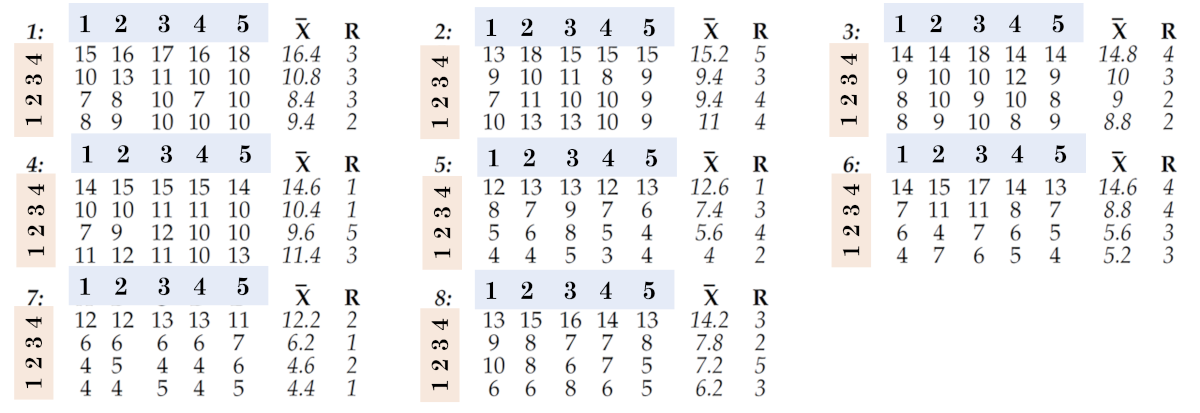
Riz. 9. La deuxième façon d'organiser les données en sous-groupes.
Valeur moyenne - 9,54 ; la plage moyenne est de 2,84, ce qui donne les limites de contrôle illustrées à la figure 10. Puisque 20 de nos 32 moyennes se situent en dehors des limites de contrôle, nous avons de nombreux signaux à interpréter. Il existe des différences notables entre les deux jours et entre les quatre cavités. De plus, le changement d'un cycle à l'autre semble être cohérent d'un sous-groupe à l'autre (carte R des plages de sous-groupes).
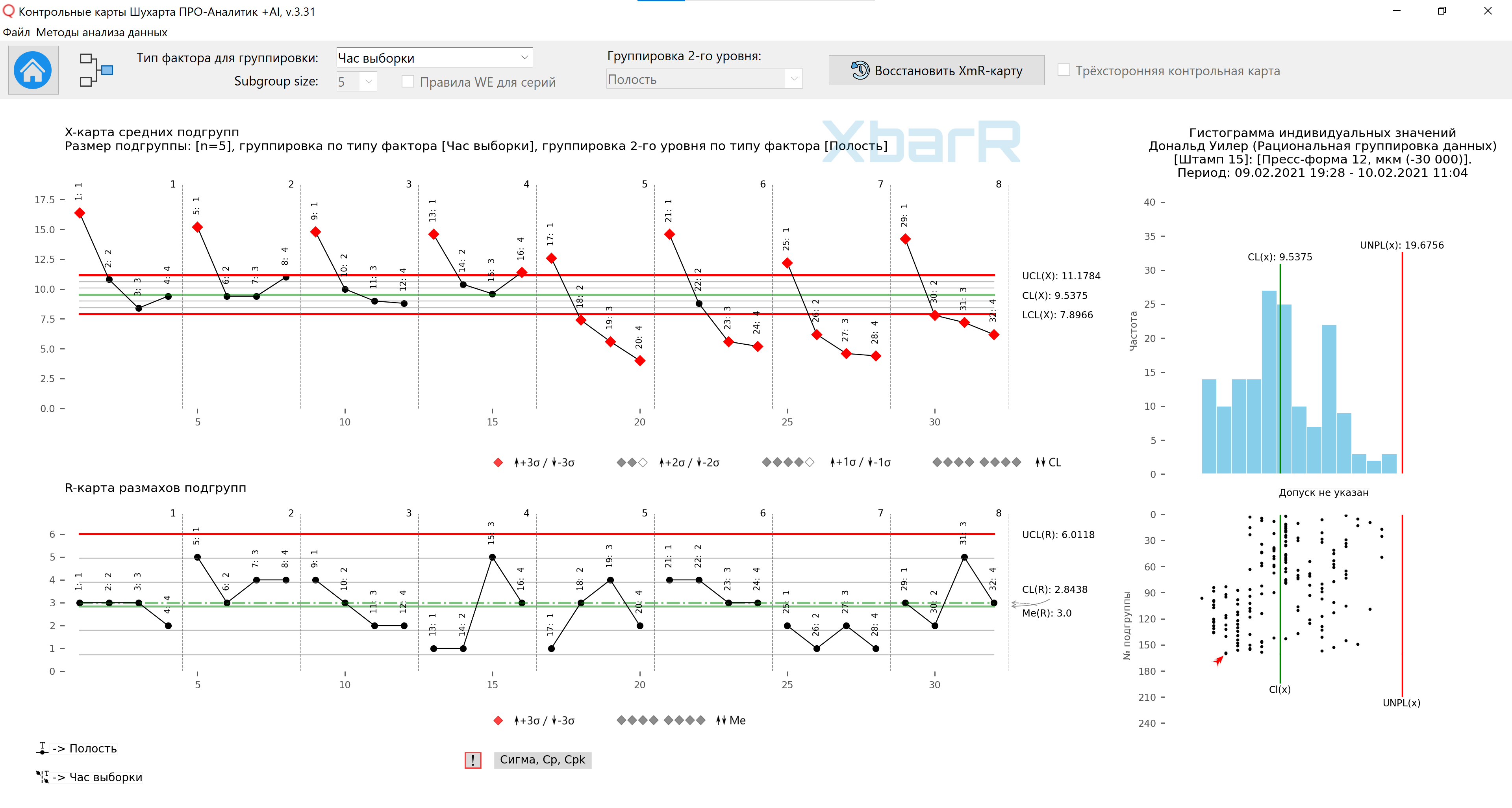
Riz. 10. Schéma des moyennes et plages des sous-groupes pour la deuxième méthode d'organisation des données en sous-groupes. Les lignes verticales divisant les séries avec des valeurs de 1 à 8 sont les heures d'échantillonnage. Signatures de tous les points - N° de cavité. Le dessin a été préparé à l'aide de notre « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » en utilisant un unique fonctions d'automatisation pour un regroupement rationnel des données construire un graphique XbarR des moyennes et des plages de sous-groupes par le type de sources de variation sélectionné (colonne avec facteurs) et la taille des sous-groupes.
Les deux méthodes ci-dessus organisant les données en sous-groupes sont techniquement correctes, mais en pratique, elles ne sont pas les mêmes car elles ne posent pas les mêmes questions sur les données. Pour comprendre cette différence, considérez la question n°3 et la question n°6.
La première organisation des données a abouti à la question n°3 : « Les différences entre cavités sont-elles cohérentes ? Le tableau des plages de groupes de la figure 8 a répondu à cette question par l'affirmative. Les différences entre les cavités sont constantes.
La deuxième organisation a abouti à la question n°6, qui demandait : « Y a-t-il des différences notables entre les cavités ? Le graphique des sous-groupes moyens de la figure 10 répond à cette question par l'affirmative. Il existe des différences notables entre les quatre cavités. La cavité (1) produit des pièces plus épaisses que les autres cavités.
Tant que vous n’aurez pas compris la différence entre la question n°3 et la question n°6, et tant que vous n’aurez pas compris comment utiliser cette différence pour répondre à vos questions, vous ne comprendrez pas le sous-groupe rationnel. C'est une compétence qui nécessite de la pratique et de la réflexion. Vous pouvez vous entraîner en répondant aux questions de la section suivante.
La troisième façon d'organiser les données en sous-groupes
Dave n'a utilisé aucune des organisations précédentes de données en sous-groupes. Au lieu de cela, il a utilisé la méthode d'organisation des données en sous-groupes, illustrée à la figure 11, pour son test de certification. Nous utilisons à nouveau chaque ligne de cinq valeurs comme un sous-groupe de taille cinq, donc les sous-groupes sont les mêmes que dans la deuxième organisation, mais maintenant nous les organisons différemment. Au lieu d’un tableau comportant 32 sous-groupes, nous aurons un tableau distinct pour chaque cavité.
Sur la figure 10, lors de la fixation de la cavité et du cycle, changez-vous de sous-groupes d'heure en heure ?
Alors, peut-on trouver des différences horaires au sein des sous-groupes ou entre sous-groupes ?
Alors, où apparaîtront les différences horaires : sur le graphique des intervalles ou sur la carte des moyennes des sous-groupes ?
Dans la figure 10, avec une horloge et une cavité fixes, changez-vous de sous-groupes au fur et à mesure que vous passez d'un cycle à l'autre ?
Alors peut-on trouver des différences entre les cycles au sein des sous-groupes ou entre sous-groupes ?
Alors, où apparaîtront les différences inter-cycles : sur le graphique des intervalles ou sur la carte des moyennes ?
Dans la figure 10, avec des horloges et des cycles fixes, changez-vous de sous-groupes à mesure que vous vous déplacez de cavité en cavité ?
Alors, où trouver les différences entre les cavités ?
Alors où apparaîtront les différences entre les cavités ?
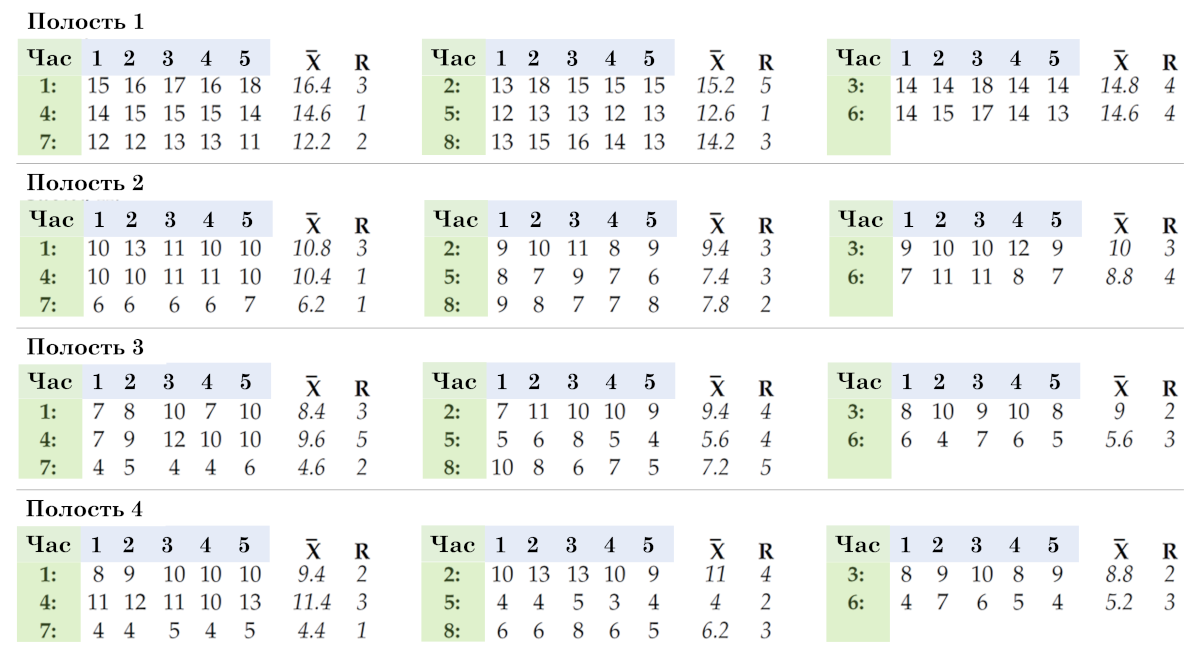
Riz. 11. La troisième façon d'organiser les données en sous-groupes.
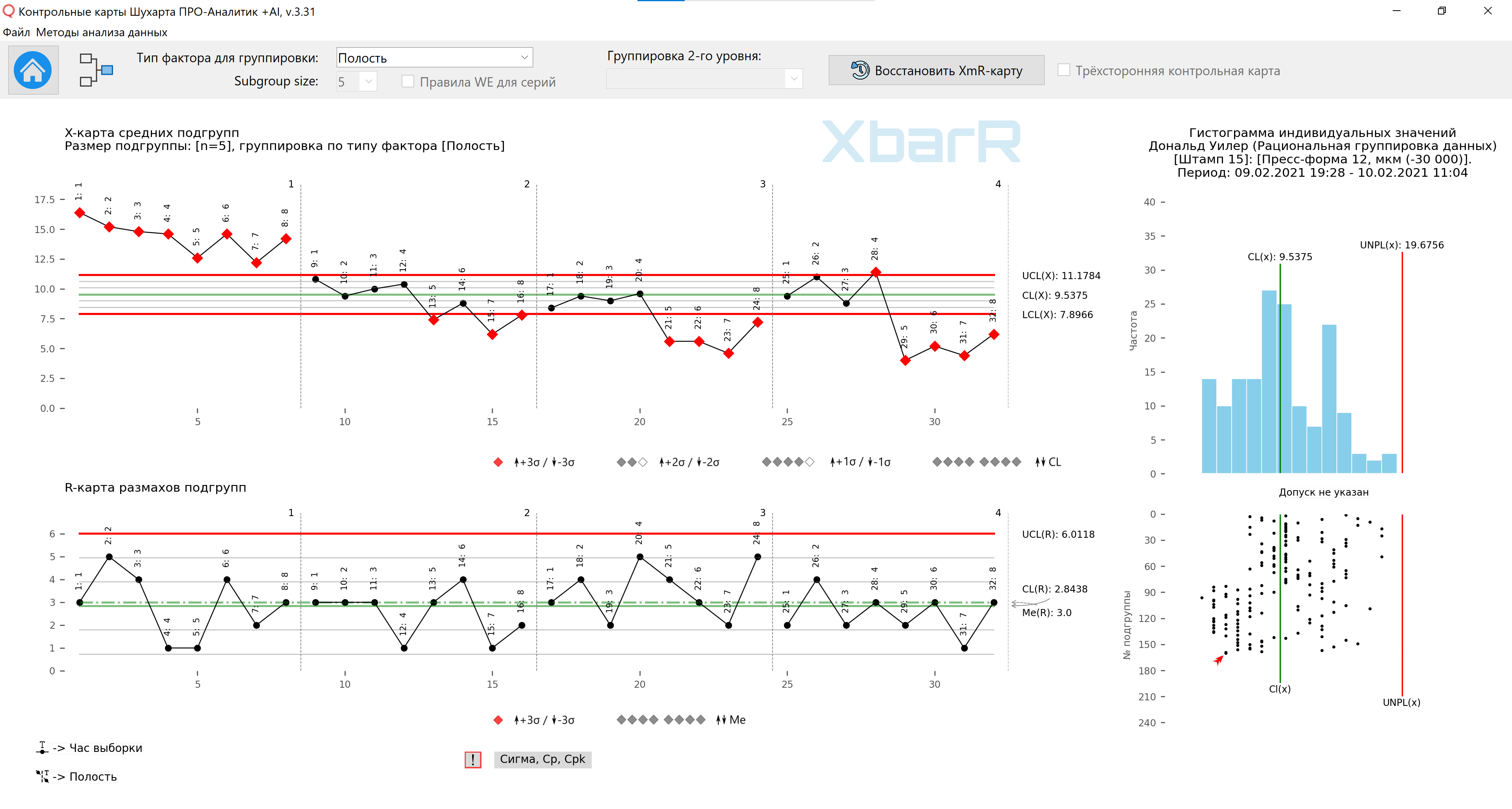
Riz. 12. Carte des moyennes et des plages de sous-groupes pour la troisième méthode d'organisation des données en sous-groupes. Lignes verticales divisant les séries avec des valeurs de 1 à 4 - Nombre de cavités. Signatures de tous les points - Heure de prélèvement. Le dessin a été préparé à l'aide de notre logiciel développé « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » en utilisant un unique fonctions d'automatisation pour un regroupement rationnel des données construire un graphique XbarR des moyennes et des plages de sous-groupes par le type de sources de variation sélectionné (colonne avec facteurs) et la taille des sous-groupes.
En traçant les quatre diagrammes sur la même échelle verticale, nous montrerons les différences entre les cavités. Évidemment, la cavité (1) rend les pièces plus épaisses et la cavité (2) est légèrement plus épaisse que les cavités (3) et (4). Sur la base de ces graphiques, Dave savait qu'il devait apporter des ajustements au formulaire. Les cavités (3) et (4) étant assez bien centrées dans la plage de tolérance, il a demandé à l'outilleur de placer des cales derrière les cavités (1) et (2).
Quelle source de variation trouve-t-on dans les diagrammes de travées ? Montre? Des cycles ? Caries?
Quelle source de variation trouve-t-on dans les graphiques moyens ? Montre? Des cycles ? Caries?
Alors, que signifient les points situés en dehors des limites de contrôle sur les graphiques de moyenne ci-dessus ?
Si vous avez rencontré des problèmes avec les questions précédentes, vous devrez peut-être relire cet article.
Vous pouvez continuer à traiter les données de la carte de contrôle de la figure 12 et, à l'aide de la fonction de limite de contrôle passe par passe, diviser les séries de données en zones de cavité individuelles en fonction des caractéristiques visibles, obtenant ainsi la confirmation du fonctionnement des différents processus avant et après le moulage. nettoyage.
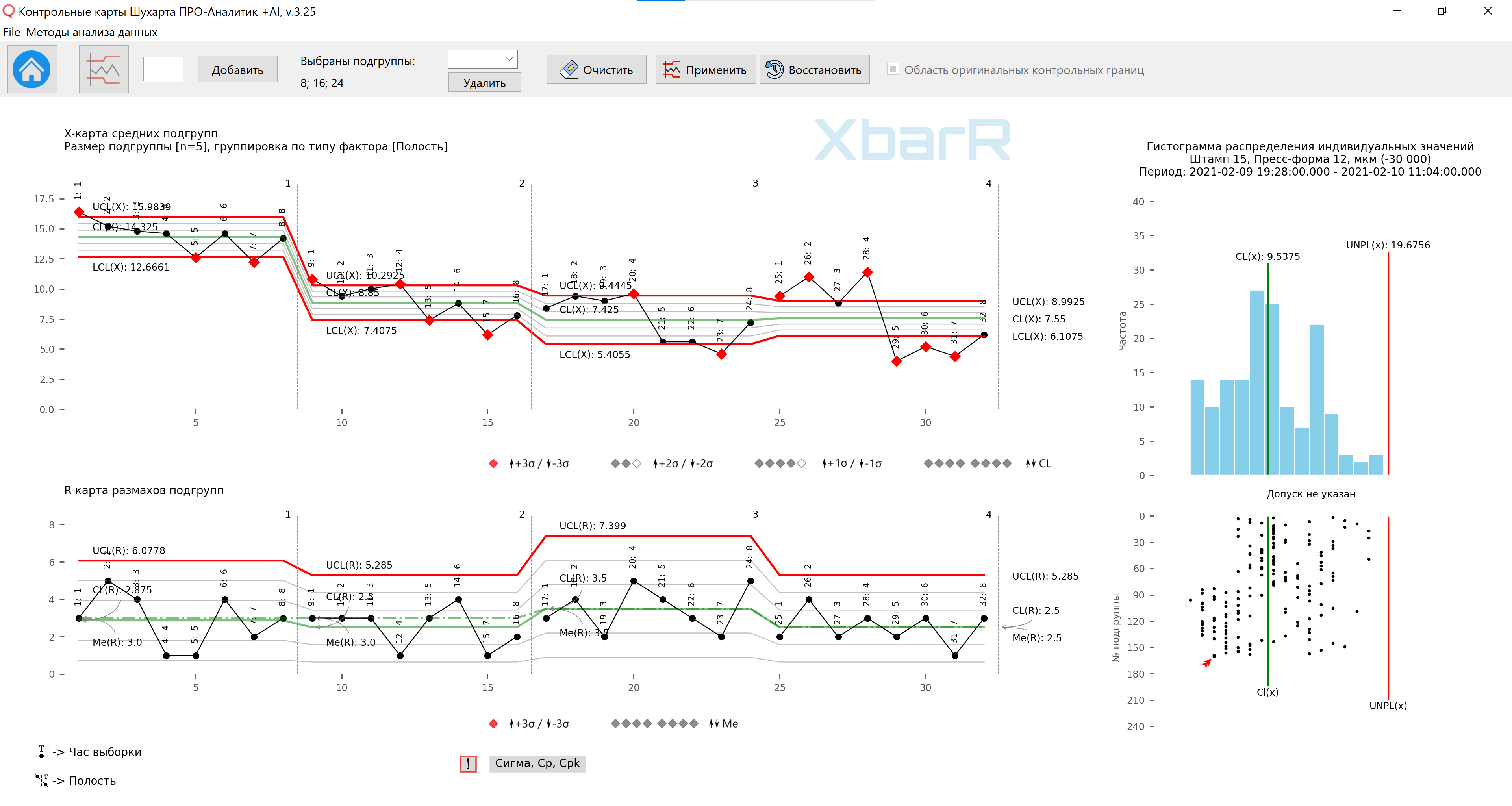
Riz. 13. Carte des moyennes et plages de sous-groupes pour la troisième méthode d'organisation des données en sous-groupes avec des limites de contrôle pour des séries individuelles de points. Lignes verticales divisant les séries avec des valeurs de 1 à 4 - Nombre de cavités. Signatures de tous les points - Heure de prélèvement. Le dessin a été préparé à l'aide de notre logiciel développé « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » en utilisant un unique fonctions d'automatisation pour un regroupement rationnel des données construire un graphique XbarR des moyennes et des plages de sous-groupes par le type de sources de variation sélectionné (colonne avec facteurs) et la taille des sous-groupes à l'aide de la fonction construire des limites de contrôle pour des séries individuelles de sous-groupes .
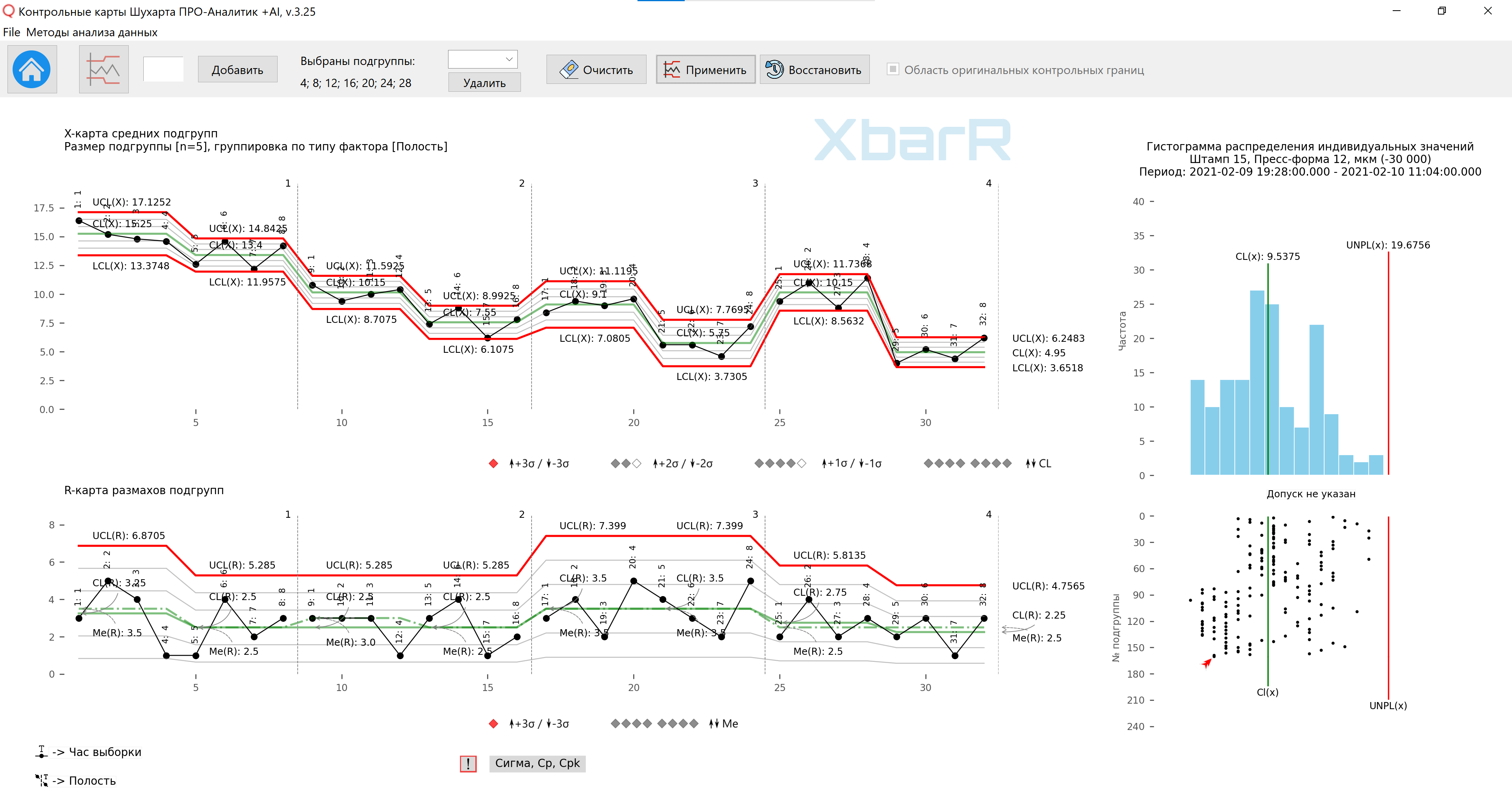
Riz. 14. Carte des moyennes et plages de sous-groupes pour la troisième méthode d'organisation des données en sous-groupes avec des limites de contrôle pour des séries individuelles de points. Lignes verticales divisant les séries avec des valeurs de 1 à 4 - Nombre de cavités. Signatures de tous les points - Heure de prélèvement. Le dessin a été préparé à l'aide de notre logiciel développé « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » en utilisant un unique fonctions d'automatisation pour un regroupement rationnel des données construire un graphique XbarR des moyennes et des plages de sous-groupes par le type de sources de variation sélectionné (colonne avec facteurs) et la taille des sous-groupes à l'aide de la fonction construire des limites de contrôle pour des séries individuelles de sous-groupes .
Résumé. Organisation des données en sous-groupes
Même si les trois manières d’organiser ces données en sous-groupes sont techniquement correctes, elles ne sont pas pratiquement équivalentes. Différentes organisations posent différentes questions sur les données et font différentes hypothèses sur les données.
La première façon d'organiser les données en sous-groupes dans les figures 7 et 8 teste la cohérence d'une cavité à l'autre et recherche les différences entre les horloges et les cycles.
La deuxième manière d'organiser les données en sous-groupes dans les figures 9 et 10 teste la cohérence d'une analyse à l'autre et recherche les différences entre les horloges et entre les cavités. Pourquoi cette organisation est-elle plus sensible que la première ?
La troisième façon d'organiser les données en sous-groupes dans les figures 11 et 12 teste également la cohérence cycle à cycle et recherche les différences entre les heures et entre les cavités, mais en plaçant les cavités sur des graphiques séparés (figure 12), il est plus facile d'identifier différences horaires et quotidiennes dans le processus. Parmi les trois façons d’organiser ces données, la troisième est la meilleure.
Regroupement intelligent des données
La clé pour obtenir des réponses à vos questions dans un graphique de moyennes et de plages de sous-groupes est de comprendre comment les deux parties du graphique XbarR posent des questions différentes. Vous contrôlez les problèmes par lesquels les sources de variation vous placez dans les sous-groupes et les sources de variation que vous placez entre les sous-groupes. Les éléments qui peuvent être différents les uns des autres doivent être répartis dans des sous-groupes différents. Les choses qui peuvent être identiques doivent appartenir au même sous-groupe.
Lorsqu'on place par exemple deux mesures ensemble dans un même sous-groupe (n=2), on conclut que les deux valeurs ont été obtenues dans sensiblement les mêmes conditions. C'est cet élément de jugement qui rend votre sous-groupe rationnel. Sans un tel jugement, votre sous-groupe pourrait bien être irrationnel.
Vous ne devriez jamais regrouper délibérément des éléments différents. Chaque sous-groupe doit être logiquement homogène. Si vous mélangez des pommes, des oranges et des bananes, vous obtiendrez peut-être une bonne salade de fruits, mais vous obtiendrez de mauvais sous-ensembles. Heureusement, le tableau de portée peut vous alerter lorsque vous regroupez systématiquement différentes choses en sous-groupes. La figure 15 montre le tableau de portée de la figure 8. Nous y avions les quatre cavités dans chaque sous-groupe.

Riz. 15. Carte des plages de sous-groupes pour la première méthode d'organisation des données en sous-groupes.
La bande mise en évidence dans la figure 15 est la bande à un sigma. Nous nous attendons à ce que 60 à 75 pour cent des valeurs de la plage se situent dans cette plage. Ici, nous obtenons 36 sur 40, soit 90 pour cent à un sigma de la ligne médiane. Lorsque les étendues de groupe s'étendent sur la ligne médiane, cela indique la présence de sous-groupes d'éléments dissemblables regroupés. Un signe courant de ce phénomène est 15 oscillations consécutives dans un sigma de la ligne centrale de la carte des oscillations. Si vous trouvez cela, vérifiez une éventuelle stratification au sein des sous-groupes. Pour comprendre comment la stratification au sein des sous-groupes affecte la carte moyenne, comparez les limites de contrôle du graphique moyen de la figure 8 (principalement LCL=4 à UCL=15) avec celles de la figure 10 (principalement LCL=8 à UCL=11).
Minimiser les variations au sein des sous-groupes. Les niveaux de bruit de fond sont déterminés par les variations au sein des sous-groupes. Tout signal devra être recherché sur ce fond de bruit. En minimisant les variations au sein des sous-groupes, vous maximisez la sensibilité de la carte de contrôle du comportement du processus.
Maximisez les possibilités de variation entre les sous-groupes. Cela nécessite de réfléchir aux types de signaux potentiels qui pourraient apparaître dans votre flux de données. Si vous souhaitez comparer deux choses, elles doivent être placées dans des sous-groupes différents. S’il est possible que deux choses soient différentes, elles doivent appartenir à des sous-groupes différents.
N'enfouissez pas les signaux dans des sous-groupes. Le regroupement n'est efficace que dans la mesure où les sous-groupes restent homogènes. Dans de nombreux domaines statistiques où l’objectif est l’estimation des paramètres, de grands volumes de données sont préférés. Mais cela ne s'applique pas aux cartes XbarR des sous-groupes de moyenne et de plage. Augmenter la taille d'un sous-groupe est un bon moyen de briser l'homogénéité des sous-groupes. Puisque les calculs supposent explicitement l’homogénéité interne des sous-groupes, l’homogénéité logique des sous-groupes est bien plus importante que la taille du sous-groupe.
Respectez le contexte de vos données. Le contexte définit la structure de vos données et est essentiel pour découvrir les causes spécifiques de variation lorsque vous modifiez votre processus. Même l’ordre des sous-groupes peut avoir de l’importance. C'est pourquoi nous utilisons généralement l'ordre temporel pour le graphique. Cependant, vous pouvez utiliser d'autres commandes si elles ont un sens dans le contexte des données.
question de sécurité
Quelle hypothèse implicite des figures 8 et 10 était incorrecte ?
Notre logiciel « Cartes de contrôle Shewhart PRO-Analyst +AI (pour Windows, Mac, Linux) » contient déjà un fichier Excel préparé avec des données pour cet article.